Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020






Date: Saturday, December 12th
Time: 1:00pm - 1:30pm
Venue: Zoom Room 4
Note: All live sessions will be screened on Singapore Time/GMT+8. Convert your time zone here.
Abstract: Shape deformation is an important component in any geometry processing toolbox. The goal is to enable intuitive deformations of single or multiple shapes or to transfer example deformations to new shapes while preserving the plausibility of the deformed shape(s). Existing approaches assume access to point-level or part-level correspondence or establish them in a preprocessing phase, thus limiting the scope and generality of such approaches. We propose DeformSyncNet, a new approach that allows consistent and synchronized shape deformations without requiring explicit correspondence information. Technically, we achieve this by encoding deformations into a class-specific idealized latent space while decoding them into an individual, model-specific linear deformation action space, operating directly in 3D. The underlying encoding and decoding are performed by specialized (jointly trained) neural networks. By design, the inductive bias of our networks results in a deformation space with several desirable properties, such as path invariance across different deformation pathways, which are then also approximately preserved in real space. We qualitatively and quantitatively evaluate our framework against multiple alternative approaches and demonstrate improved performance.
Author(s)/Presenter(s):
Minhyuk Sung, Adobe Research, United States of America
Zhenyu Jiang, University of Texas at Austin, United States of America
Panos Achlioptas, Stanford University, United States of America
Niloy J. Mitra, University College London (UCL), Adobe Research, United States of America
Leonidas J. Guibas, Stanford University, United States of America

Abstract: Patterns, which are collections of elements arranged in regular or near-regular arrangements, are an important graphic art form and widely used due to their elegant simplicity and aesthetic appeal. When a pattern is encoded as a flat image without the underlying structure, manually editing the pattern is tedious and challenging as one has to both preserve the individual element shapes and their original relative arrangements. State-of-the-art deep learning frameworks that operate at the pixel level are unsuitable for manipulating such patterns. Specifically, these methods can easily disturb the shapes of the individual elements or their arrangement, and thus fail to preserve the latent structures of the input patterns. We present a novel differentiable compositing operator using pattern elements and use it to discover structures, in the form of a layered representation of graphical objects, directly from raw pattern images. This operator allows us to adapt current deep learning based image methods to effectively handle patterns. We evaluate our method on a range of patterns and demonstrate superiority in the context of pattern manipulations when compared against state-of-the-art pixel- or point-based alternatives.
Author(s)/Presenter(s):
Pradyumna Reddy, University College London (UCL), United Kingdom
Paul Guerrero, Adobe Research, United Kingdom
Matt Fisher, Adobe Research, United States of America
Wilmot Li, Adobe Research, United States of America
Niloy J. Mitra, UCL, Adobe Research, United Kingdom

Abstract: Most attempts to represent 3D shapes for deep learning have focused on volumetric grids, multi-view images and point clouds. In this paper we look at the most popular representation of 3D shapes in computer graphics---a triangular mesh---and ask how it can be utilized within deep learning. The few attempts to answer this question propose to adapt convolutions \& pooling to suit Convolutional Neural Networks (CNNs). This paper proposes a very different approach, termed MeshWalker, to learn the shape directly from a given mesh. The key idea is to represent the mesh by random walks along the surface, which "explore" the mesh's geometry and topology. Each walk is organized as a list of vertices, which in some manner imposes regularity on the mesh. The walk is fed into a Recurrent Neural Network (RNN) that "remembers" the history of the walk. We show that our approach achieves state-of-the-art results for two fundamental shape analysis tasks: shape classification and semantic segmentation. Furthermore, even a very small number of examples suffices for learning. This is highly important, since large datasets of meshes are difficult to acquire.
Author(s)/Presenter(s):
Alon Lahav, Technion – Israel Institute of Technology, Israel
Ayellet Tal, Technion – Israel Institute of Technology, Israel

Abstract: In this paper we propose an approach for automatically computing multiple high-quality near-isometric maps between a pair of 3D shapes. Our method is fully automatic and does not rely on user-provided landmarks or descriptors. This allows us to analyze the full space of maps and extract multiple diverse and accurate solutions, rather than optimizing for a single optimal correspondence as done in previous approaches. To achieve this, we first propose a compact tree structure based on the spectral map representation for encoding and enumerate possible rough initializations, and a novel efficient approach for refining them to dense pointwise maps. This leads to the first method capable of both producing multiple high-quality correspondences across shapes and revealing the symmetry structure of a shape without a priori information. In addition, we demonstrate through extensive experiments that our method is robust and results in more accurate correspondences than state-of-the-art for shape matching and symmetry detection.
Author(s)/Presenter(s):
Jing Ren, KAUST, Saudi Arabia
Simone Melzi, Ecole Polytechnique, France
Maks Ovsjanikov, Ecole Polytechnique, France
Peter Wonka, KAUST, Saudi Arabia

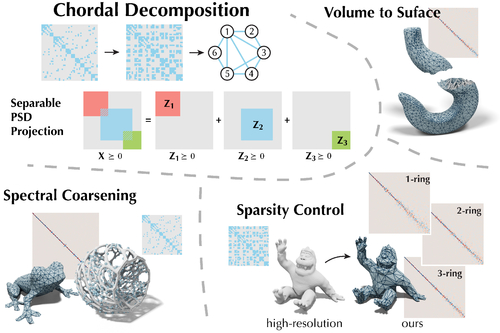
Abstract: We introduce a novel solver to significantly reduce the size of a geometric operator while preserving its spectral properties at the lowest frequencies. We use chordal decomposition to formulate a convex optimization problem which allows the user to control the operator sparsity pattern. This allows for a trade-off between the spectral accuracy of the operator and the cost of its application. We efficiently minimize the energy with a change of variables and achieve state-of-the-art results on spectral coarsening. Our solver further enables novel applications including volume-to-surface approximation and detaching the operator from the mesh, i.e., one can produce a mesh tailor-made for visualization and optimize an operator separately for computation.
Author(s)/Presenter(s):
Honglin Chen, University of Toronto, Canada
Hsueh-Ti Derek Liu, University of Toronto, Canada
Alec Jacobson, University of Toronto, Canada
David I.W. Levin, University of Toronto, Canada
Abstract: This paper presents a novel approach to learn and detect distinctive regions on 3D shapes. Unlike previous works, which require labeled data, our method is unsupervised. We conduct the analysis on point sets sampled from 3D shapes, then formulate and train a deep neural network for an unsupervised shape clustering task to learn local and global features for distinguishing shapes with respect to a given shape set. To drive the network to learn in an unsupervised manner, we design a clustering-based nonparametric softmax classifier with an iterative re-clustering of shapes, and an adapted contrastive loss for enhancing the feature embedding quality and stabilizing the learning process. By then, we encourage the network to learn the point distinctiveness on the input shapes. We extensively evaluate various aspects of our approach and present its applications for distinctiveness-guided shape retrieval, sampling, and view selection in 3D scenes.
Author(s)/Presenter(s):
Xianzhi Li, Chinese University of Hong Kong, Hong Kong
Lequan Yu, Chinese University of Hong Kong, Hong Kong
Chi-Wing Fu, Chinese University of Hong Kong, Hong Kong
Daniel Cohen-Or, Tel Aviv University, Israel
Pheng-Ann Heng, Chinese University of Hong Kong, Hong Kong

