Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020





Date: Sunday, December 13th
Time: 10:00am - 10:30am
Venue: Zoom Room 7
Note: All live sessions will be screened on Singapore Time/GMT+8. Convert your time zone here.
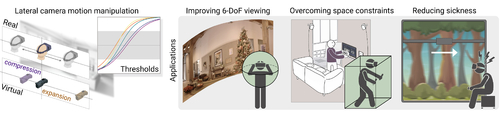
Abstract: Virtual Reality (VR) systems increase immersion by reproducing users’ movements in the real world. However, several works have shown that this real-to-virtual mapping does not need to be precise in order to convey a realistic experience. Being able to alter this mapping has many potential applications, since achieving an accurate real-to-virtual mapping is not always possible due to limitations in the capture or display hardware, or in the physical space available. In this work, we measure detection thresholds for lateral translation gains of virtual camera motion in response to the corresponding head motion under natural viewing, and in the absence of locomotion, so that virtual camera movement can be either compressed or expanded while these manipulations remain undetected. Finally, we propose three applications for our method, addressing three key problems in VR: improving 6-DoF viewing for captured 360º footage, overcoming physical constraints, and reducing simulator sickness. We have further validated our thresholds and evaluated our applications by means of additional user studies confirming that our manipulations remain imperceptible, and showing that (i) compressing virtual camera motion reduces visible artifacts in 6-DoF, hence improving perceived quality, (ii) virtual expansion allows for completion of virtual tasks within a reduced physical space, and (iii) simulator sickness may be alleviated in simple scenarios when our compression method is applied.
Author(s)/Presenter(s):
Ana Serrano, Universidad de Zaragoza, Max-Planck-Institut für Informatik, Germany
Daniel Martin, Universidad de Zaragoza, Spain
Diego Gutierrez, Universidad de Zaragoza, Spain
Karol Myszkowski, Max-Planck-Institut für Informatik, Germany
Belen Masia, Universidad de Zaragoza, Spain
Abstract: Virtual reality headsets are becoming increasingly popular, yet it remains difficult for casual users to capture immersive 360° VR panoramas. State-of-the-art approaches require capture times of usually far more than a minute and are often limited in their supported range of head motion. We introduce OmniPhotos, a novel approach for quickly and casually capturing high-quality 360° panoramas with motion parallax. Our approach requires a single sweep with a consumer 360° video camera as input, which takes less than 3 seconds to capture with a rotating selfie stick or 10 seconds handheld. This is the fastest capture time for any VR photography approach supporting motion parallax by an order of magnitude. We improve the visual rendering quality of our OmniPhotos by minimising vertical distortion using a novel deformable proxy geometry, which we fit to a sparse 3D reconstruction of captured scenes. In addition, the 360° input views significantly expand the available viewing area and thus the range of motion. We have captured more than 50 OmniPhotos and show video results for a large variety of scenes.
Author(s)/Presenter(s):
Tobias Bertel, University of Bath, United Kingdom
Mingze Yuan, University of Bath, United Kingdom
Reuben Lindroos, University of Bath, United Kingdom
Christian Richardt, University of Bath, United Kingdom

Abstract: Virtual and augmented reality (VR/AR) displays crucially rely on stereoscopic rendering to enable perceptually realistic user experiences. Yet, existing neareye display systems ignore the gaze-dependent shift of the no-parallax point in the human eye. Here, we introduce a gaze-contingent stereo rendering technique that models this effect and conduct several user studies to validate its effectiveness. Our findings include experimental validation of the location of the no-parallax point, which we then use to demonstrate significant improvements of disparity and shape distortion in a VR setting, and consistent alignment of physical and digitally rendered objects across depths in optical see-through AR. Our work shows that gaze-contingent stereo rendering improves perceptual realism and depth perception of emerging wearable computing systems.
Author(s)/Presenter(s):
Brooke Krajancich, Stanford University, United States of America
Petr Kellnhofer, Stanford University, Raxium, United States of America
Gordon Wetzstein, Stanford University, United States of America

Abstract: We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
Author(s)/Presenter(s):
Mohamed Elgharib, Max-Planck-Institut für Informatik, Germany
Mohit Mendiratta, Max-Planck-Institut für Informatik, Germany
Justus Thies, Technische Universität München (TUM), Germany
Matthias Niessner, Technische Universität München (TUM), Germany
Hans-Peter Seidel, Max-Planck-Institut für Informatik, Germany
Ayush Tewari, Max-Planck-Institut für Informatik, Germany
Vladislav Golyanik, Max-Planck-Institut für Informatik, Germany
Christian Theobalt, Max-Planck-Institut für Informatik, Germany

Abstract: Audio recordings contain rich information about sound sources and their properties such as the location, loudness, and frequency of events. One prevalent component in sound recordings is the sound texture, which contains a massive number of events. In such a texture, there can be some distinct and repeated sounds that we term as a foreground sound. Birds chirping in the wind is one such decorative sound texture with the chirping as a foreground sound and the wind as a background texture. To render these decorative sound textures in real-time and with high quality, we create two-layer Markov Models to enable smooth transitions from sound grain to sound grain and propose a hierarchical scheme to generate Head-Related Transfer Function filters for localization cues of sounds represented as area/volume sources. Moreover, during the synthesis stage, we provide control over the frequency and intensity of sounds for customization. Lastly, foreground sounds are often blended into background textures such as the sound of rain splats on car surfaces becoming submerged in the background rain. We develop an extraction component that outperforms existing learning-based methods to facilitate our synthesis with perceptible foreground sounds and well-defined textures.
Author(s)/Presenter(s):
Jinta Zheng, Oregon State University, United States of America
Shih-Hsuan Hung, Oregon State University, United States of America
Kyle Hiebel, Oregon State University, United States of America
Yue Zhang, Oregon State University, United States of America
Abstract: Compressed textures are indispensable in most 3D graphics applications to reduce memory traffic and increase performance. For higher-quality graphics, the number and size of textures in an application have continuously increased. Additionally, the ETC2 texture format, which is mandatory in OpenGL ES 3.0, OpenGL 4.3, and Android 4.3 (and later versions), requires more complex texture compression than the traditional ETC1 format. As a result, texture compression becomes more and more time-consuming. To accelerate ETC2 compression, we introduce two new compression techniques, named QuickETC2. The first technique is an early compression-mode decision scheme. Instead of testing all ETC1/2 modes to compress a texel block, we select proper modes for each block by exploiting the luma difference of the block to reduce unnecessary compression overhead. The second technique is a fast luma-based T- and H-mode compression method. When clustering each texel into two groups, we replace the 3D RGB space with the 1D luma space and quickly find the two groups that have the minimum luma differences. We also selectively perform the T- or H-mode and reduce its distance candidates, according to the luma differences of each group. We have implemented both techniques with AVX2 intrinsics to exploit SIMD parallelism. According to our experiments, QuickETC2 can compress more than 2000 1K×1K-sized images per second on an octa-core CPU.
Author(s)/Presenter(s):
Jae-Ho Nah, LG Electronics, South Korea


