Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020





Date: Thursday, December 10th
Time: 10:00am - 10:30am
Venue: Zoom Room 3
Note: All live sessions will be screened on Singapore Time/GMT+8. Convert your time zone here.
Abstract: Tracking and reconstructing the 3D pose and geometry of two hands in interaction is a challenging problem that has a high relevance for several human-computer interaction applications, including AR/VR, robotics, or sign language recognition. Existing works are either limited to simpler tracking settings (e.g., considering only a single hand or two spatially separated hands), or rely on less ubiquitous sensors, such as depth cameras. In contrast, in this work we present the first real-time method for motion capture of skeletal pose and 3D surface geometry of hands from a single RGB camera that explicitly considers close interactions. In order to address the inherent depth ambiguities in RGB data, we propose a novel multi-task CNN that regresses multiple complementary pieces of information, including segmentation, dense matchings to a 3D hand model, and 2D keypoint positions, together with newly proposed intra-hand relative depth and inter-hand distance maps. These predictions are subsequently used in a generative model fitting framework in order to estimate pose and shape parameters of a 3D hand model for both hands. We experimentally verify the individual components of our RGB two-hand tracking and 3D reconstruction pipeline through an extensive ablation study. Moreover, we demonstrate that our approach offers previously unseen two-hand tracking performance from RGB, and quantitatively and qualitatively outperforms existing RGB-based methods that were not explicitly designed for two-hand interactions. Moreover, our method even performs on-par with depth-based real-time methods.
Author(s)/Presenter(s):
Jiayi Wang, Max-Planck-Institut für Informatik, Germany
Franziska Mueller, Max-Planck-Institut für Informatik, Germany
Florian Bernard, Max-Planck-Institut für Informatik, Technische Universität München (TUM), Germany
Suzanne Sorli, Universidad Rey Juan Carlos, Spain
Oleksandr Sotnychenko, Max-Planck-Institut für Informatik, Germany
Neng Qian, Max-Planck-Institut für Informatik, Germany
Miguel A. Otaduy, Universidad Rey Juan Carlos, Spain
Dan Casas, Universidad Rey Juan Carlos, Spain
Christian Theobalt, Max-Planck-Institut für Informatik, Germany

Abstract: Many of the actions that we take with our hands involve self-contact and occlusion: shaking hands, making a fist, or interlacing our fingers while thinking. This use of of our hands illustrates the importance of tracking hands through self-contact and occlusion for many applications in computer vision and graphics, but existing methods for tracking hands and faces are not designed to treat the extreme amounts of self-contact and self-occlusion exhibited by common hand gestures. By extending recent advances in vision-based tracking and physically based animation, we present the first algorithm capable of tracking high-fidelity hand deformations through highly self-contacting and self-occluding hand gestures, for both single hands and two hands. By constraining a vision-based tracking algorithm with a physically based deformable model, we obtain an algorithm that is robust to the ubiquitous self-interactions and massive self-occlusions exhibited by common hand gestures, allowing us to track two hand interactions and some of the most difficult possible configurations of a human hand.
Author(s)/Presenter(s):
Breannan Smith, Facebook Reality Labs, United States of America
Chenglei Wu, Facebook Reality Labs, United States of America
He Wen, Facebook Reality Labs, United States of America
Patrick Peluse, Facebook Reality Labs, United States of America
Yaser Sheikh, Facebook Reality Labs, United States of America
Jessica Hodgins, Facebook AI Research, United States of America
Takaaki Shiratori, Facebook Reality Labs, United States of America

Abstract: Portrait relighting aims to render a face image under different lighting conditions. Existing methods do not explicitly consider some challenging lighting effects such as specular and shadow, and thus may fail in handling extreme lighting conditions. In this paper, we propose a novel framework that explicitly models multiple channels for single image portrait relighting, including the facial albedo, geometry as well as two lighting effects, i.e., specular and shadow. These channels are finally composed to generate the relit results via deep neural networks. Current datasets do not support us to learn such multiple channel modeling. Therefore, we present a large-scale dataset with the ground-truths of the channels, enabling us to train the deep neural networks in a supervised manner. Furthermore, we develop a novel module named Lighting guided Feature Modulation (LFM). In contrast to existing methods which simply incorporate the given lighting in the bottleneck of a network, LFM fuses the lighting by layer-wise feature modulation to deliver more convincing results. Extensive experiments demonstrate that our proposed method achieves better results and is able to generate challenging lighting effects.
Author(s)/Presenter(s):
Zhibo Wang, Tsinghua University, China
Xin Yu, University of Technology Sydney, Australia
Ming Lu, Intel Labs, China
Quan Wang, SenseTime, China
Chen Qian, SenseTime, China
Feng Xu, Tsinghua University, China

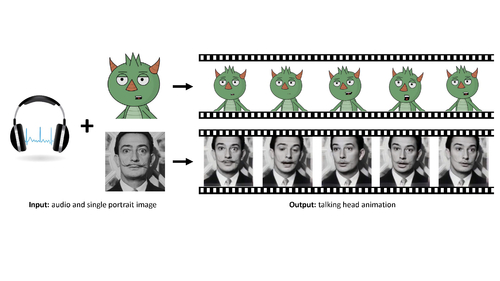
Abstract: We present a method that generates expressive talking-head videos from a single facial image with audio as the only input. In contrast to previous attempts to learn direct mappings from audio to raw pixels for creating talking faces, our method first disentangles the content and speaker information in the input audio signal. The audio content robustly controls the motion of lips and nearby facial regions, while the speaker information determines the specifics of facial expressions and the rest of the talking-head dynamics. Another key component of our method is the prediction of facial landmarks reflecting the speaker-aware dynamics. Based on this intermediate representation, our method works with many portrait images in a single unified framework, including artistic paintings, sketches, 2D cartoon characters, Japanese mangas, and stylized caricatures. In addition, our method generalizes well for faces and characters that were not observed during training. We present an extensive quantitative and qualitative evaluation of our method, in addition to user studies, demonstrating generated talking-heads of significantly higher quality compared to prior state-of-the-art methods.
Author(s)/Presenter(s):
Yang Zhou, University of Massachusetts Amherst, United States of America
Xintong Han, Huya Inc, China
Eli Shechtman, Adobe Research, United States of America
Jose Echevarria, Adobe Research, United States of America
Evangelos Kalogerakis, University of Massachusetts Amherst, United States of America
Dingzeyu Li, Adobe Research, United States of America
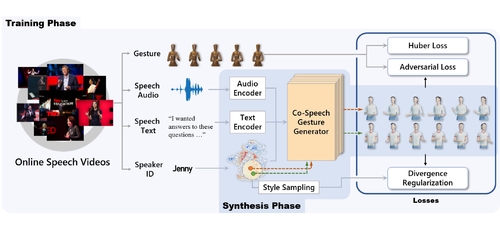
Abstract: For human-like agents, including virtual avatars and social robots, making proper gestures while speaking is crucial in human--agent interaction. Co-speech gestures enhance interaction experiences and make the agents look alive. However, it is difficult to generate human-like gestures due to the lack of understanding of how people gesture. Data-driven approaches attempt to learn gesticulation skills from human demonstrations, but the ambiguous and individual nature of gestures hinders learning. In this paper, we present an automatic gesture generation model that uses the multimodal context of speech text, audio, and speaker identity to reliably generate gestures. By incorporating a multimodal context and an adversarial training scheme, the proposed model outputs gestures that are human-like and that match with speech content and rhythm. We also introduce a new quantitative evaluation metric for gesture generation models. Experiments with the introduced metric and subjective human evaluation showed that the proposed gesture generation model is better than existing end-to-end generation models. We further confirm that our model is able to work with synthesized audio in a scenario where contexts are constrained, and show that different gesture styles can be generated for the same speech by specifying different speaker identities in the style embedding space that is learned from videos of various speakers. All the code and data is available at https://github.com/ai4r/Gesture-Generation-from-Trimodal-Context.
Author(s)/Presenter(s):
Youngwoo Yoon, Electronics and Telecommunications Research Institute (ETRI), Korea Advanced Institute of Science and Technology (KAIST), South Korea
Bok Cha, University of Science and Technology, Electronics and Telecommunications Research Institute (ETRI), South Korea
Joo-Haeng Lee, Electronics and Telecommunications Research Institute (ETRI), University of Science and Technology, South Korea
Minsu Jang, Electronics and Telecommunications Research Institute (ETRI), South Korea
Jaeyeon Lee, Electronics and Telecommunications Research Institute (ETRI), South Korea
Jaehong Kim, Electronics and Telecommunications Research Institute (ETRI), South Korea
Geehyuk Lee, Korea Advanced Institute of Science and Technology (KAIST), South Korea