Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020





Date: Saturday, December 12th
Time: 1:30pm - 2:00pm
Venue: Zoom Room 8
Note: All live sessions will be screened on Singapore Time/GMT+8. Convert your time zone here.
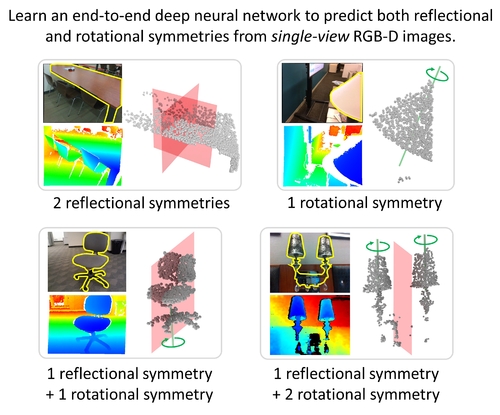
Abstract: We study the problem of symmetry detection of 3D shapes from single-view RGB-D images, where severely missing data renders geometric detection approach infeasible. We propose an end-to-end deep neural network which is able to predict both reflectional and rotational symmetries of 3D objects present in the input RGB-D image. Directly training a deep model for symmetry prediction, however, can quickly run into the issue of overfitting. We adopt a multi-task learning approach. Aside from symmetry axis prediction, our network is also trained to predict symmetry correspondences. In particular, given the 3D points present in the RGB-D image, our network outputs for each 3D point its symmetric counterpart corresponding to a specific predicted symmetry. In addition, our network is able to detect for a given shape multiple symmetries of different types. We also contribute a benchmark of 3D symmetry detection based on single-view RGB-D images. Extensive evaluation on the benchmark demonstrates the strong generalization ability of our method, in terms of high accuracy of both symmetry axis prediction and counterpart estimation. In particular, our method is robust in handling unseen object instances with large variation in shape, multi-symmetry composition, as well as novel object categories.
Author(s)/Presenter(s):
Yifei Shi, National University of Defense Technology (NUDT), China
Junwen Huang, National University of Defense Technology (NUDT), China
Hongjia Zhang, National University of Defense Technology (NUDT), China
Xin Xu, National University of Defense Technology (NUDT), China
Szymon Rusinkiewicz, Princeton University, United States of America
Kai Xu, National University of Defense Technology (NUDT), China
Abstract: We present a new framework for sketch-based modeling and animation of 3D organic shapes that can work entirely in an intuitive 2D domain, enabling a playful, casual experience. Unlike previous sketch-based tools, our approach does not require a tedious part-based multi-view workflow with the explicit specification of an animation rig. Instead, we combine 3D inflation with a novel rigidity-preserving, layered deformation model, ARAP-L, to produce a smooth 3D mesh that is immediately ready for animation. Moreover, the resulting model can be animated from a single viewpoint — and without the need to handle inter-penetrations, as required by previous approaches. We demonstrate the benefit of our approach on a variety of examples produced by inexperienced users as well as professional animators. For less experienced users, our single-view approach offers a simpler modeling and animating experience than working in a 3D environment, while for professionals, it offers a quick and casual workspace for ideation.
Author(s)/Presenter(s):
Marek Dvorožňák, CTU in Prague, FEE, Czech Republic
Daniel Sýkora, CTU in Prague, FEE, Czech Republic
Cassidy Curtis, Google Research, United States of America
Brian Curless, Google Research, University of Washington, United States of America
Olga Sorkine-Hornung, ETH Zürich, Switzerland
David Salesin, Google Research, United States of America

Abstract: The creation of high-fidelity computer-generated (CG) characters used in film and gaming requires intensive manual labor and a comprehensive set of facial assets to be captured with complex hardware, resulting in high cost and long production cycles. In order to simplify and accelerate this digitization process, we propose a framework for the automatic generation of high-quality dynamic facial assets, including rigs which can be readily deployed for artists to polish. Our framework takes a single scan as input to generate a set of personalized blendshapes, dynamic and physically-based textures, as well as secondary facial components (e.g., teeth and eyeballs). Built upon a facial database consisting of pore-level details, with over $4,000$ scans of varying expressions and identities, we adopt a self-supervised neural network to learn personalized blendshapes from a set of template expressions. We also model the joint distribution between identities and expressions, enabling the inference of the full set of personalized blendshapes with dynamic appearances from a single neutral input scan. Our generated personalized face rig assets are seamlessly compatible with cutting-edge industry pipelines for facial animation and rendering. We demonstrate that our framework is robust and effective by inferring on a wide range of novel subjects, and illustrate compelling rendering results while animating faces with generated customized physically-based dynamic textures.
Author(s)/Presenter(s):
Jiaman Li, University of Southern California, USC Institute for Creative Technologies, United States of America
Zhengfei Kuang, University of Southern California, USC Institute for Creative Technologies, United States of America
Yajie Zhao, USC Institute for Creative Technologies, United States of America
Mingming He, USC Institute for Creative Technologies, United States of America
Karl Bladin, USC Institute for Creative Technologies, United States of America
Hao Li, USC Institute for Creative Technologies; Pinscreen, Inc., United States of America

Abstract: In this paper, we present iOrthoPredictor, a novel system to visually predict the teeth alignment effect in a single photograph. Our system takes a frontal face image of a patient with visible malpositioned teeth along with a corresponding 3D teeth model as input, and generates a facial image with aligned teeth, mimicking the real orthodontic treatment effect. The key enabler of our method is an effective disentanglement of an explicit representation of the teeth geometry from the in-mouth appearance, where the accuracy of teeth geometry transformation is ensured by the 3D teeth model while the in-mouth appearance is modeled as a latent variable. The disentanglement enables us to achieve fine-scale geometry control over the alignment while retaining the original teeth appearance attributes and lighting conditions. The whole pipeline consists of three deep neural networks: a U-Net architecture to explicitly extract the 2D teeth silhouette maps representing the teeth geometry in the input photo, a novel multilayer perceptron (MLP) based network to predict the aligned 3D teeth model, and an encoder-decoder based generative model to synthesize the in-mouth appearance conditional on the original teeth appearance and the aligned teeth geometry. Extensive experimental results and a user study demonstrate that iOrthoPredictor is effective in generating high-quality visual prediction of teeth alignment effect, and applicable to industrial orthodontic treatments.
Author(s)/Presenter(s):
Lingchen Yang, State Key Laboratory of CAD & CG, Zhejiang University, China
Zefeng Shi, State Key Laboratory of CAD & CG, Zhejiang University, China
Yiqian Wu, State Key Laboratory of CAD & CG, Zhejiang University, China
Xiang Li, Zhejiang University, China
Kun Zhou, Zhejiang University, China
Hongbo Fu, City University of Hong Kong, Hong Kong
Youyi Zheng, State Key Laboratory of CAD & CG, Zhejiang University; Zhejiang University, China

Abstract: In computer graphics populating a large-scale natural scene with plants in a fashion that both reflects the complex interrelationships and diversity present in real ecosystems and is computationally efficient enough to support iterative authoring remains an open problem. Ecosystem simulations embody many of the botanical influences, such as sunlight, temperature, and moisture, but require hours to complete, while synthesis from statistical distributions tends not to capture fine-scale variety and complexity. Instead, we leverage real-world data and machine learning to derive a canopy height model (CHM) for unseen terrain provided by the user. Canopy trees are then fitted to the resulting CHM through a constrained iterative process that optimizes for a given distribution of species, and, finally, an understorey layer is synthesised using distributions derived from biome-specific undergrowth simulations. Such a hybrid data-driven approach has the advantage that it implicitly incorporates subtle biotic, abiotic, and disturbance factors and evidences accepted biological behaviour, such as self-thinning, climatic adaptation, and gap dynamics.
Author(s)/Presenter(s):
Konrad Kapp, University of Cape Town, South Africa
James Gain, University of Cape Town, South Africa
Eric Guérin, Institut National des Sciences Appliquées (INSA) de Lyon, France
Eric Galin, Université Lyon 1, France
Adrien Peytavie, Université Lyon 1, France


