Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020





Date: Saturday, December 12th
Time: 10:30am - 11:00am
Venue: Zoom Room 5
Note: All live sessions will be screened on Singapore Time/GMT+8. Convert your time zone here.
Abstract: Editing of portrait images is a very popular and important research topic with a large variety of applications. For ease of use, control should be provided via a semantically meaningful parameterization that is akin to computer animation controls. The vast majority of existing techniques do not provide such intuitive and fine-grained control, or only enable coarse editing of a single isolated control parameter. Very recently, high-quality semantically controlled editing has been demonstrated, however only on synthetically created StyleGAN images. We present the first approach for embedding real portrait images in the latent space of StyleGAN, which allows for intuitive editing of the head pose, facial expression, and scene illumination in the image. Semantic editing in parameter space is achieved based on StyleRig, a pretrained neural network that maps the control space of a 3D morphable face model to the latent space of the GAN. We design a novel hierarchical non-linear optimization problem to obtain the embedding. An identity preservation energy term allows spatially coherent edits while maintaining facial integrity. Our approach runs at interactive frame rates and thus allows the user to explore the space of possible edits. We evaluate our approach on a wide set of portrait photos, compare it to the current state of the art, and validate the effectiveness of its components in an ablation study.
Author(s)/Presenter(s):
Ayush Tewari, Max-Planck-Institut für Informatik, Germany
Mohamed Elgharib, Max-Planck-Institut für Informatik, Germany
Malikarjun B R, Max-Planck-Institut für Informatik, Germany
Florian Bernard, Max-Planck-Institut für Informatik, Germany
Hans-Peter Seidel, Max-Planck-Institut für Informatik, Germany
Patrick Pérez, Valeo.ai, France
Michael Zollhöfer, Stanford University, United States of America
Christian Theobalt, Max-Planck-Institut für Informatik, Germany

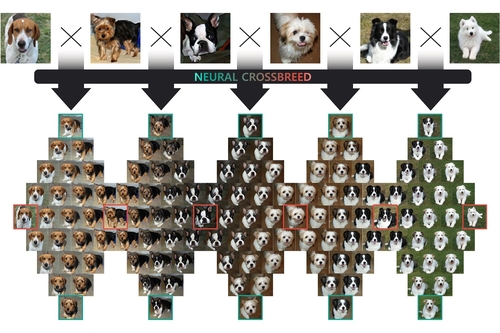
Abstract: We propose Neural Crossbreed, a feed-forward neural network that can learn a semantic change of input images in a latent space to create the morphing effect. Because the network learns a semantic change, a sequence of meaningful intermediate images can be generated without requiring the user to specify explicit correspondences. In addition, the semantic change learning makes it possible to perform the morphing between the images that contain objects with significantly different poses or camera views. Furthermore, just as in conventional morphing techniques, our morphing network can handle shape and appearance transitions separately by disentangling the content and the style transfer for rich usability. We prepare a training dataset for morphing using a pre-trained BigGAN, which generates an intermediate image by interpolating two latent vectors at an intended morphing value. This is the first attempt to address image morphing using a pre-trained generative model in order to learn semantic transformation. The experiments show that Neural Crossbreed produces high quality morphed images, overcoming various limitations associated with conventional approaches. In addition, Neural Crossbreed can be further extended for diverse applications such as multi-image morphing, appearance transfer, and video frame interpolation.
Author(s)/Presenter(s):
Sanghun Park, KAIST, Visual Media Lab, South Korea
Kwanggyoon Seo, KAIST, Visual Media Lab, South Korea
Junyong Noh, KAIST, Visual Media Lab, South Korea
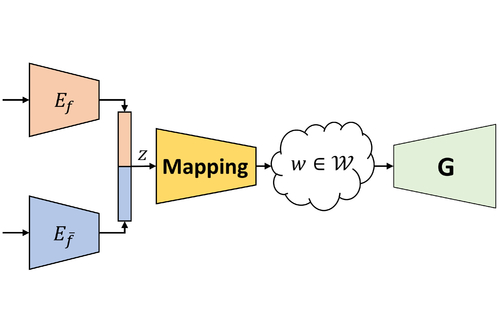
Abstract: Learning disentangled representations of data is a fundamental problem in artificial intelligence. Specifically, disentangled latent representations allow generative models to control and compose the disentangled factors in the synthesis process. Current methods, however, require extensive supervision and training, or instead, noticeably compromise quality. In this paper, we present a method that learns how to represent data in a disentangled way, with minimal supervision, manifested solely using available pre-trained networks. Our key insight is to decouple the processes of disentanglement and synthesis, by employing a leading pre-trained unconditional image generator, such as StyleGAN. By learning to map into its latent space, we leverage both its state-of-the-art quality generative power, and its rich and expressive latent space, without the burden of training it. We demonstrate our approach on the complex and high dimensional domain of human heads. We evaluate our method qualitatively and quantitatively, and exhibit its success with de-identification operations and with temporal identity coherency in image sequences. Through extensive experimentation, we show that our method successfully disentangles identity from other facial attributes, surpassing existing methods, even though they require more training and supervision.
Author(s)/Presenter(s):
Yotam Nitzan, Tel Aviv University, Israel
Amit Bermano, Tel Aviv University, Israel
Yangyan Li, Alibaba AI Labs, China
Daniel Cohen-Or, Tel Aviv University, Israel
Abstract: Western color comics and Japanese-style screened manga are two popular comic styles. They mainly differ in the style of region-filling. However, the conversion between the two region-filling styles is very challenging, and manually done currently. In this paper, we identify that the major obstacle in the conversion between the two filling styles stems from the difference between the fundamental properties of screened region-filling and colored region-filling. To resolve this obstacle, we propose a screentone variational autoencoder, ScreenVAE, to map the screened manga to an intermediate domain. This intermediate domain can summarize local texture characteristics and is interpolative. With this domain, we effectively unify the properties of screening and color-filling, and ease the learning for bidirectional translation between screened manga and color comics. To carry out the bidirectional translation, we further propose a network to learn the translation between the intermediate domain and color comics. Our model can generate superior screened manga given a color comic, and generate color comic that retains the original screening intention by the bitonal manga artist. Several results are shown to demonstrate the effectiveness and convenience of the proposed method. We also demonstrate how the intermediate domain can assist other applications such as manga inpainting and photo-to-comic conversion.
Author(s)/Presenter(s):
Minshan XIE, The Chinese University of Hong Kong, Hong Kong
Chengze LI, The Chinese University of Hong Kong, Hong Kong
Xueting LIU, Caritas Institute of Higher Education, Hong Kong
Tien-Tsin WONG, The Chinese University of Hong Kong, Hong Kong

Abstract: The paradigm of image-to-image translation is leveraged for the benefit of sketch stylization via transfer of geometric textural details. Lacking the necessary volumes of data for standard training of translation systems, we advocate for operation at the patch level, where a handful of stylized sketches provide ample mining potential for patches featuring basic geometric primitives. Operating at the patch level necessitates special consideration of full sketch translation, as individual translation of patches with no regard to neighbors is likely to produce visible seams and artifacts at patch borders. Aligned pairs of styled and plain primitives are combined to form input hybrids containing styled elements around the border and plain elements within, and given as input to a seamless translation (ST) generator, whose output patches are expected to reconstruct the fully styled patch. An adversarial addition promotes generalization and robustness to diverse geometries at inference time, forming a simple and effective system for arbitrary sketch stylization, as demonstrated upon a variety of styles and sketches.
Author(s)/Presenter(s):
Noa Fish, Tel Aviv University, Israel
Lilach Perry, Tel Aviv University, Israel
Amit Bermano, Tel Aviv University, Israel
Daniel Cohen-Or, Tel Aviv University, Israel


