Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020





Date: Sunday, December 13th
Time: 1:00pm - 1:30pm
Venue: Zoom Room 4
Note: All live sessions will be screened on Singapore Time/GMT+8. Convert your time zone here.
Abstract: This paper presents the idea of mono-nizing binocular videos and a framework to effectively realize it. Mono-nize means we purposely convert a binocular video into a regular monocular video with the stereo information implicitly encoded in a visual but nearly-imperceptible form. Hence, we can impartially distribute and show the mononized video as an ordinary monocular video. Unlike ordinary monocular videos, we can restore from it the original binocular video and show it on a stereoscopic display. To start, we formulate an encoding-and-decoding framework with the pyramidal deformable fusion module to exploit long-range correspondences between the left and right views, a quantization layer to suppress the restoring artifacts, and the compression noise simulation module to resist the compression noise introduced by modern video codecs. Our framework is self-supervised, as we articulate our objective function with loss terms defined on the input: a monocular term for creating the mononized video, an invertibility term for restoring the original video, and a temporal term for frame-to-frame coherence. Further, we conducted extensive experiments to evaluate our generated mononized videos and restored binocular videos for diverse types of images and 3D movies. Quantitative results on both standard metrics and user perception studies show the effectiveness of our method.
Author(s)/Presenter(s):
Wenbo HU, The Chinese University of Hong Kong, Hong Kong
Menghan XIA, The Chinese University of Hong Kong, Hong Kong
Chi-Wing FU, The Chinese University of Hong Kong, Hong Kong
Tien-Tsin WONG, The Chinese University of Hong Kong, Hong Kong

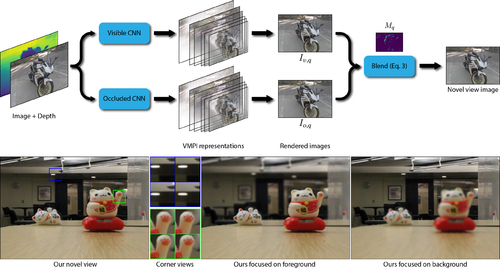
Abstract: We propose a learning-based approach to synthesize a light field with a small baseline from a single image. We synthesize the novel view images by first using a convolutional neural network (CNN) to promote the input image into a layered representation of the scene. We extend the multiplane image (MPI) representation by allowing the disparity of the layers to be inferred from the input image. We show that, compared to the original MPI representation, our representation models the scenes more accurately. Moreover, we propose to handle the visible and occluded regions separately through two parallel networks. The synthesized images using these two networks are then combined through a soft occlusion mask to generate the final results. To effectively train the networks, we introduce a large-scale light field dataset of over 2,000 unique scenes containing a wide range of objects. We demonstrate that our approach synthesizes high-quality light fields on a variety of scenes, better than the state-of-the-art methods.
Author(s)/Presenter(s):
Qinbo Li, Texas A&M University, United States of America
Nima Khademi Kalantari, Texas A&M University, United States of America
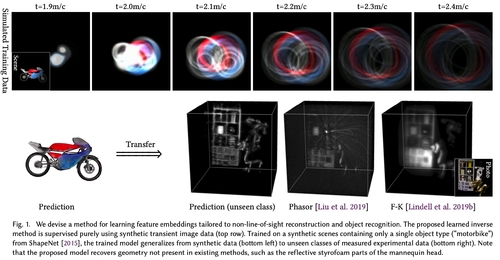
Abstract: Objects obscured by occluders are considered lost in the images acquired by conventional camera systems, prohibiting both visualization and understanding of such hidden objects. Non-line-of-sight methods (NLOS) aim at recovering information about hidden scenes, which could help make medical imaging less invasive, improve the safety of autonomous vehicles, and potentially enable capturing unprecedented high-definition RGB-D data sets that include geometry beyond the directly visible parts. Recent NLOS methods have demonstrated scene recovery from time-resolved pulse-illuminated measurements encoding occluded objects as faint indirect reflections. Unfortunately, these systems are fundamentally limited by the quartic intensity fall-off for diffuse scenes. With laser illumination limited by eye-safety limits, recovery algorithms must tackle this challenge by incorporating scene priors. However, existing NLOS reconstruction algorithms do not facilitate learning scene priors. Even if they did, datasets that allow for such supervision do not exist, and successful encoder-decoder networks and generative adversarial networks fail for real-world NLOS data. In this work, we close this gap by learning hidden scene feature representations tailored to both reconstruction and recognition tasks such as classification or object detection, while still relying on physical models at the feature level. We overcome the lack of real training data with a generalizable architecture that can be trained in simulation. We learn the differentiable scene representation jointly with the reconstruction task using a differentiable transient renderer in the objective, and demonstrate that it generalizes to unseen classes and unseen real-world scenes, unlike existing encoder-decoder architectures and generative adversarial networks. The proposed method allows for end-to-end training for different NLOS tasks, such as image reconstruction, classification, and object detection, while requiring an order of magnitude less memory than existing methods and running at real-time rates. We demonstrate hidden view synthesis, RGB-D reconstruction, classification, and object detection in the hidden scene in an end-to-end fashion.
Author(s)/Presenter(s):
Wenzheng Chen, University of Toronto, Canada
Fangyin Wei, Princeton University, United States of America
Kyros Kutulakos, University of Toronto, Canada
Szymon Rusinkiewicz, Princeton University, United States of America
Felix Heide, Princeton University, United States of America
Abstract: Neural networks are often quantized to use reduced-precision arithmetic, as it greatly improves their storage and computational costs. This approach is commonly used in applications like image classification and natural language processing, however, using a quantized network for the reconstruction of HDR images can lead to a significant loss in image quality. In this paper, we introduce QW-Net, a neural network for image reconstruction, where close to 95% of the computations can be implemented with 4-bit integers. This is achieved using a combination of two U-shaped networks that are specialized for different tasks, a feature extraction network based on the U-Net architecture, coupled to a filtering network that reconstructs the output image. The feature extraction network has more computational complexity but is more resilient to quantization errors. The filtering network, on the other hand, has significantly fewer computations but requires higher precision. Our network uses renderer-generated motion vectors to recurrently warp and accumulate previous frames, producing temporally stable results with significantly better quality than TAA, a widely used technique in current games.
Author(s)/Presenter(s):
Manu Mathew Thomas, University of California Santa Cruz, United States of America
Karthik Vaidyanathan, Intel Corporation, United States of America
Gabor Liktor, Intel Corporation, United States of America
Angus G. Forbes, University of California Santa Cruz, United States of America


