Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
Pre-recorded Sessions: From 4 December 2020 | Live Sessions: 10 – 13 December 2020
4 – 13 December 2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020
#SIGGRAPHAsia | #SIGGRAPHAsia2020





Date: Saturday, December 12th
Time: 11:00am - 11:30am
Venue: Zoom Room 7
Note: All live sessions will be screened on Singapore Time/GMT+8. Convert your time zone here.
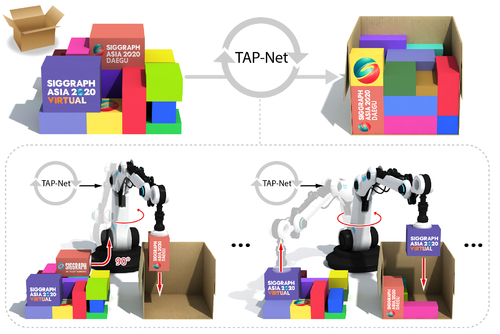
Abstract: We introduce the transport-and-pack problem and develop a neural optimization model to solve it based on reinforcement learning. Given an initial spatial configuration of boxes, we seek an efficient method to iteratively transport and pack the boxes compactly into a target container. In general, packing alone is a well-known, difficult combinatorial optimization problem. Due to obstruction and accessibility constraints, our problem has to add a transport planning dimension to the already immense search space. Using a learning-based approach, a trained network can learn and encode solution patterns to guide the solution of new problem instances instead of executing an expensive online search. In our work, we represent the various constraints using a precedence graph and train a neural network, coined TAP-Net, using reinforcement learning to reward efficient packing. The network is built on a recurrent neural network (RNN) which inputs the current precedence graph, as well as the current box packing state of the target container, and it outputs the next box to pack, as well as its orientation. We train our network on randomly generated initial box configurations, without supervision, via policy gradients to learn optimal TAP policies to maximize packing efficiency. We demonstrate the performance of TAP-Net on a variety of examples, evaluating the network through ablation studies and comparisons to baselines and heuristic search methods. We also show that our network generalizes well to larger problem instances, when trained on small-sized inputs.
Author(s)/Presenter(s):
Ruizhen Hu, Shenzhen University, China
Juzhan Xu, Shenzhen University, China
Bin Chen, Shenzhen University, China
Minglun Gong, University of Guelph, Canada
Hao Zhang, Simon Fraser University, Canada
Hui Huang, Shenzhen University, China
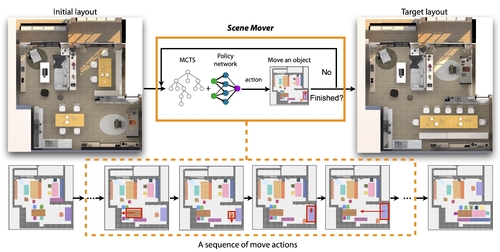
Abstract: We propose a novel approach for automatically generating a move plan for scene arrangement. Given a scene like an apartment with many furniture objects, to transform its layout into another layout, one would need to determine a collision-free move plan. It could be challenging to design this plan manually because the furniture objects may block the way of each other if not moved properly; and there is a large complex search space of move action sequences that grow exponentially with the number of objects. To tackle this challenge, we propose a learning-based approach to generate a move plan automatically. At the core of our approach is a Monte Carlo tree that encodes possible states of the layout, based on which a search is performed to move a furniture object appropriately in the current layout. We trained a policy neural network embedded with an LSTM module for estimating the best actions to take in the expansion step and simulation step of the Monte Carlo tree search process. Leveraging the power of deep reinforcement learning, the network learned how to make such estimations through millions of trials of moving objects. We demonstrated our approach for moving objects under different scenarios and constraints. We also evaluated our approach on synthetic and real-world layouts, comparing its performance with that of humans and other baseline approaches.
Author(s)/Presenter(s):
Hanqing Wang, Beijing Institute of Technology, China
Wei Liang, Beijing Institute of Technology, China
Lap-Fai Yu, George Mason University, United States of America
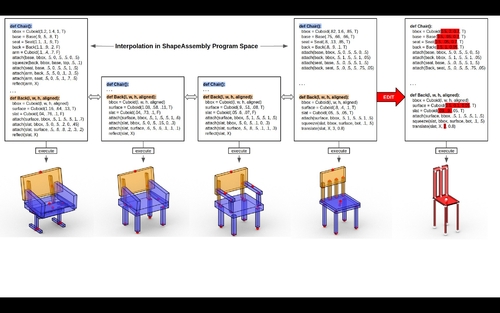
Abstract: Manually authoring 3D shapes is difficult and time consuming; generative models of 3D shapes offer compelling alternatives. Procedural representations are one such possibility: they offer high-quality and editable results but are difficult to author and often produce outputs with limited diversity. On the other extreme are deep generative models: given enough data, they can learn to generate any class of shape but their outputs have artifacts and the representation is not editable. In this paper, we take a step towards achieving the best of both worlds for novel 3D shape synthesis. First, we propose ShapeAssrmbly, a domain-specific "assembly-language'' for 3D shape structures. ShapeAssembly programs construct shape structures by declaring cuboid part proxies and attaching them to one another, in a hierarchical and symmetrical fashion. ShapeAssembly functions are parameterized with continuous free variables, so that one program structure is able to capture a family of related shapes. We show how to extract ShapeAssembly programs from existing shape structures in the PartNet dataset. Then we train a deep generative model, a hierarchical sequence VAE, that learns to write novel ShapeAssembly programs. Our approach leverages the strengths of each representation: the program captures the subset of shape variability that is interpretable and editable, and the deep generative model captures variability and correlations across shape collections that is hard to express procedurally. We evaluate our approach by comparing shapes output by our generated programs to those from other recent shape structure synthesis models. We find that our generated shapes are more plausible and physically-valid than those of other methods. Additionally, we assess the latent spaces of these models, and find that ours is better structured and produces smoother interpolations. As an application, we use our generative model and differentiable program interpreter to infer and fit shape programs to unstructured geometry, such as point clouds.
Author(s)/Presenter(s):
R. Kenny Jones, Brown University, United States of America
Theresa Barton, Brown University, United States of America
Xianghao Xu, Brown University, United States of America
Kai Wang, Brown University, United States of America
Ellen Jiang, Brown University, United States of America
Paul Guerrero, Adobe Research, United Kingdom
Niloy J. Mitra, University College London (UCL), United Kingdom
Daniel Ritchie, Brown University, United States of America
Abstract: Marker-less 3D human motion capture from a single colour camera has seen significant progress. However, it is a very challenging and severely ill-posed problem. In consequence, even the most accurate state-of-the-art approaches have significant limitations. Purely kinematic formulations on the basis of individual joints or skeletons, and the frequent frame-wise reconstruction in state-of-the-art methods greatly limit 3D accuracy and temporal stability compared to multi-view or marker-based motion capture. Further, captured 3D poses are often physically incorrect and biomechanically implausible, or exhibit implausible environment interactions (floor penetration, foot skating, unnatural body leaning and strong shifting in depth), which is problematic for any use case in computer graphics. We, therefore, present PhysCap, the first algorithm for physically plausible, real-time and marker-less human 3D motion capture with a single colour camera at 25 fps. Our algorithm first captures 3D human poses purely kinematically. To this end, a CNN infers 2D and 3D joint positions, and subsequently, an inverse kinematics step finds space-time coherent joint angles and global 3D pose. Next, these kinematic reconstructions are used as constraints in a real-time physics-based pose optimiser that accounts for environment constraints (e.g., collision handling and floor placement), gravity, and biophysical plausibility of human postures. Our approach employs a combination of ground reaction force and residual force for plausible root control, and uses a trained neural network to detect foot contact events in images. Our method captures physically plausible and temporally stable global 3D human motion, without physically implausible postures, floor penetrations or foot skating, from video in real time and in general scenes. PhysCap achieves state-of-the-art accuracy on established pose benchmarks, and we propose new metrics to demonstrate the improved physical plausibility and temporal stability.
Author(s)/Presenter(s):
Soshi Shimada, Max-Planck-Institut für Informatik, Saarland Informatics Campus, Germany
Vladislav Golyanik, Max-Planck-Institut für Informatik, Saarland Informatics Campus, Germany
Weipeng Xu, Facebook Reality Labs, United States of America
Christian Theobalt, Max-Planck-Institut für Informatik, Saarland Informatics Campus, Germany

Abstract: Data-driven modelling and synthesis of motion is an active research area with applications that include animation, games, and social robotics. This paper introduces a new class of probabilistic, generative, and controllable motion-data models based on normalising flows. Models of this kind can describe highly complex distributions, yet can be trained efficiently using exact maximum likelihood, unlike GANs or VAEs. Our proposed model is autoregressive and uses LSTMs to enable arbitrarily long time-dependencies. Importantly, is is also causal, meaning that each pose in the output sequence is generated without access to poses or control inputs from future time steps; this absence of algorithmic latency is important for interactive applications with real-time motion control. The approach can in principle be applied to any type of motion since it does not make restrictive, task-specific assumptions regarding the motion or the character morphology. We evaluate the models on motion-capture datasets of human and quadruped locomotion. Objective and subjective results show that randomly-sampled motion from the proposed method outperforms task-agnostic baselines and attains a motion quality close to recorded motion capture.
Author(s)/Presenter(s):
Gustav Eje Henter, KTH Royal Institute of Technology, Sweden
Simon Alexanderson, KTH Royal Institute of Technology, Sweden
Jonas Beskow, KTH Royal Institute of Technology, Sweden

Abstract: MotioNet is a deep neural network that reconstructs a kinematic skeleton from monocular video, and directly outputs the complete, commonly used, motion representation in character animation.
Author(s)/Presenter(s):
Mingyi Shi, Shandong University, China
Kfir Aberman, Tel Aviv University, Beijing Film Academy, Israel
Andreas Aristidou, University of Cyprus, Interdisciplinary Center Herzliya Efi Arazi School of Computer Science, Cyprus
Taku Komura, University of Edinburgh, United Kingdom
Dani Lischinski, Tel Aviv The Hebrew University of Jerusalem, Israel
Daniel Cohen-Or, Tel Aviv University, Israel
Baoquan Chen, Peking University, China

